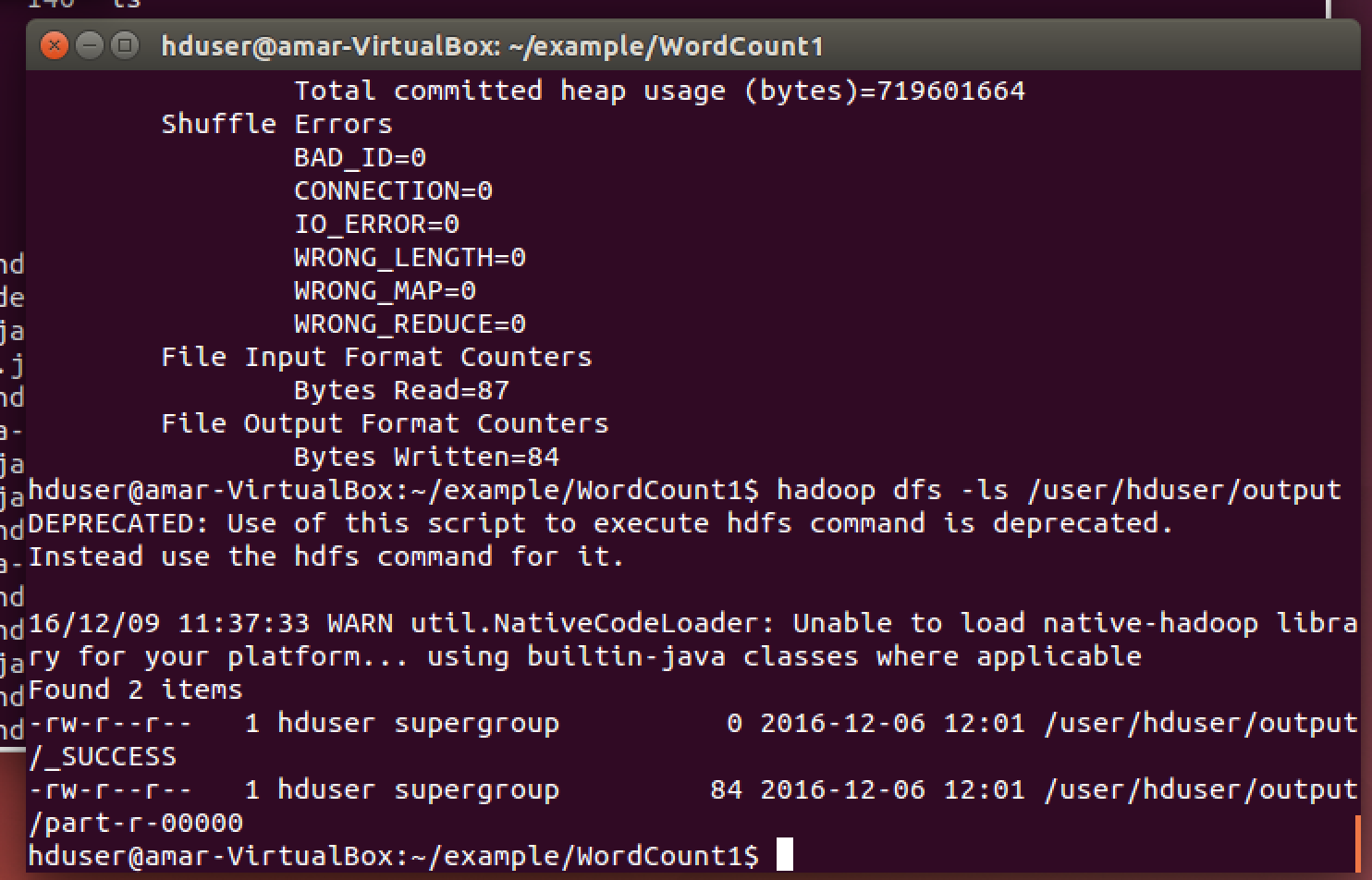
HBase Commands
./bin/hbase shell woir> list woir> status woir> version woir> table_help woir> whoami woir> create ‘woir’, ‘family data’, ’work data’ woir> disable ‘woir’ woir> is_disabled ‘table name’ woir> is_disabled ‘woir’ woir> disable_all ‘amar.*’ woir> enable ‘woir’ woir> scan ‘woir’ woir> is_enabled ‘table name’ woir> is_enabled ‘woir’ woir> describe ‘woir’ woir> alter ‘woir’, NAME => ‘family data’,…
Read more