NoSQLBench – Setup and Evaluating Cassandra Performance
- Download :
- Download the latest binary nb file using this link https://github.com/nosqlbench/nosqlbench/blob/main/DOWNLOADS.md
- Download the latest binary nb file using this link https://github.com/nosqlbench/nosqlbench/blob/main/DOWNLOADS.md
- Sample Yaml File :
- # nb -v run driver=cql yaml=cql-keyvalue tags=phase:schema host=hostip
scenarios:
default:
– run driver=cql tags==phase:schema threads==1 cycles==UNDEF
– run driver=cql tags==phase:rampup cycles===TEMPLATE(rampup-cycles,100000) threads=auto
– run driver=cql tags==phase:main cycles===TEMPLATE(main-cycles,1000000 threads=auto
bindings:
seq_key: Mod(<<keycount:10000>>); ToString() -> String
seq_value: HashedFileExtractToString(‘data/lorem_ipsum_full.txt’,0,96)
rw_key: <<keydist:Uniform(0,10000)->int>>; ToString() -> String
# rw_key: <<keydist:Uniform(0,10000)->int>>; ToString() -> String
#rw_value: Hash(); <<valdist:Uniform(0,10000)->int>>; ToString() -> String
rw_value: HashedFileExtractToString(‘data/lorem_ipsum_full.txt’,0,96)
blocks:
– name: schema
tags:
phase: schema
params:
prepared: false
statements:
– create-keyspace: |
create keyspace if not exists <<keyspace:amar>>
WITH replication = {‘class’: ‘SimpleStrategy’, ‘replication_factor’: ‘<<rf:1>>’}
AND durable_writes = true;
tags:
name: create-keyspace
– create-table: |
create table if not exists <<keyspace:amar>>.<<table:keyvalue>> (
key text,
value text,
PRIMARY KEY (key)
)
tags:
name: create-table
– name: rampup
tags:
phase: rampup
params:
cl: <<write_cl:LOCAL_QUORUM>>
statements:
– rampup-insert: |
insert into <<keyspace:amar>>.<<table:keyvalue>>
(key, value)
values ({seq_key},{seq_value});
tags:
name: rampup-insert
– name: verify
tags:
phase: verify
type: read
params:
cl: <<read_cl:LOCAL_QUORUM>>
statements:
– verify-select: |
select * from <<keyspace:amar>>.<<table:keyvalue>> where key={seq_key};
verify-fields: key->seq_key, value->seq_value
tags:
name: verify
– name: main-read
tags:
phase: main
type: read
params:
ratio: 80
cl: <<read_cl:LOCAL_QUORUM>>
statements:
– main-select: |
select * from <<keyspace:amar>>.<<table:keyvalue>> where key={rw_key};
tags:
name: main-select
instrument: true
– name: main-write
tags:
phase: main
type: write
params:
ratio: 20
cl: <<write_cl:LOCAL_QUORUM>>
statements:
– main-insert: |
insert into <<keyspace:amar>>.<<table:keyvalue>>
(key, value) values ({rw_key}, {rw_value});
tags:
name: main-insert
instrument: true
- How to generate the yaml file from workload :
- ./nb workload=cql-keyvalue –copy=cql-keyvalue.yaml
- To see the list of workloads , run the below command
- ./nb –list-workloads
- The yaml file is a list named blocks and Each block has tags. We use these tags to indicate the phase of the workload. In this example, the phase is schema, which is short for schema creation.
- ./nb run driver=cql workload=cql-keyvalue tags=phase:schema
- when we execute above command it refers to the schema phase in workload. Below is the one example block
- blocks: – tags : phase: schema
- Sample command of nb
- ./nb run yaml=/home/woir/Downloads/test/cql-keyvalue.yaml tags=phase:schema cycles=10000 –progress console:1s –report-csv-to /home/woir/Downloads/test/ threads=auto
- yaml : location of yaml file
- tags : Give the tag name for write/read operation. The tags are differ based on the yaml file
- cycles: Give the no of cycles for read/write operations.
- –progress: To the progress of run
- –report-csv-to : Give the path to store csv files
- ./nb run yaml=/home/woir/Downloads/test/cql-keyvalue.yaml tags=phase:schema cycles=10000 –progress console:1s –report-csv-to /home/woir/Downloads/test/ threads=auto
- How to create keyspace and table using command line:
- ./nb run driver=cql yaml=<Yaml FilePath> tags=phase:schema host=<IP Adress>
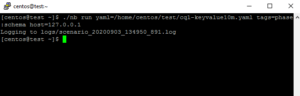
- ./nb run driver=cql yaml=<Yaml FilePath> tags=phase:schema host=<IP Adress>
- How to Write/Insert Data into table using command line:
- ./nb run driver=cql yaml=<Yaml FilePath> tags=phase:rampup host=<IP Adress> cycles=10000 –progress console:1s
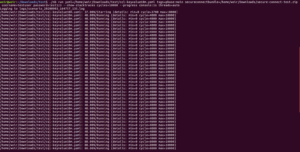
- ./nb run driver=cql yaml=<Yaml FilePath> tags=phase:rampup host=<IP Adress> cycles=10000 –progress console:1s
- Reading Data:
- ./nb run driver=cql yaml=<Yaml FilePath> tags=phase:main,type=read host=<IP Adress> cycles=10000 –progress console:1s
- Running Mixed (read/write operations):
- ./nb run driver=cql yaml=<Yaml FilePath> tags=phase:main host=<IP Adress> cycles=10000 –progress console:1s
- change the read and write ratios in yaml file as per run
- Running all the commands together:
- we can create or add new scenarios in workloads that allow us to automate a sequence of activities. The default scenario name will be selected automatically if the user doesn’t specify one.We can specify the name of the workload and the named scenario on the command line
- we can run the scenario with following command
- ./nb ./cql-keyvalue.yaml default
- Running individual blocks
- we can run the individual block with following command
- ./nb ./cql-keyvalue.yaml ramup
- Here is an example ,ramup block added in worload
- we can run the individual block with following command
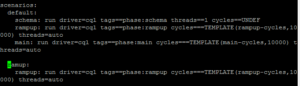
- Running individual phase:
- In the blocks section, we have the tag to name the phase
- Example
- blocks: – tags: phase: ramup
- Example
- we can run individual phase with following command
- ./nb run yaml=<path of file> tags=phase:ramup cycles=1000 –progress console:1s
- In the blocks section, we have the tag to name the phase
One Response
[…] 2. NoSqlBench setup here: Know More […]
Comments are closed.