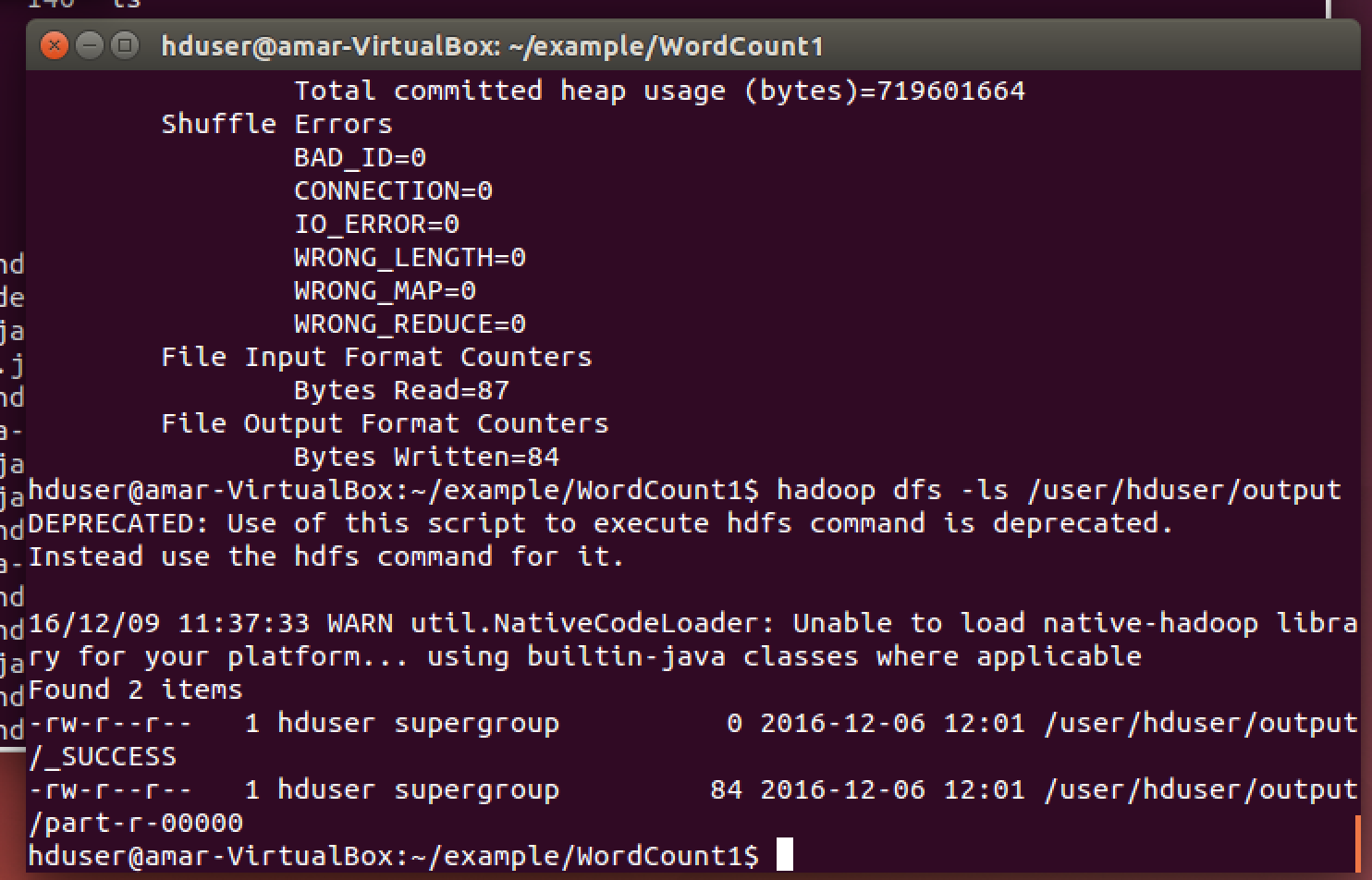
HBase Commands
./bin/hbase shell woir> list woir> status woir> version woir> table_help woir> whoami woir> create ‘woir’, ‘family data’, ’work data’ woir> disable ‘woir’ woir> is_disabled ‘table name’ woir> is_disabled ‘woir’ woir> disable_all ‘amar.*’ woir> enable ‘woir’ woir> scan ‘woir’ woir> is_enabled ‘table name’ woir> is_enabled ‘woir’ woir> describe ‘woir’ woir> alter ‘woir’, NAME => ‘family data’,…
Read more

Hive Installation
Download woir@woir-VirtualBox:/tmp$ wget http://archive.apache.org/dist/hive/hive-2.1.0/apache-hive-2.1.0-bin.tar.gz woir@woir-VirtualBox:/tmp$ tar xvzf apache-hive-2.1.0-bin.tar.gz -C /home/woir copy paste following in the /home/woir/sourceme export HIVE_HOME=/home/woir/apache-hive-2.1.0-bin export HIVE_CONF_DIR=/home/woir/apache-hive-2.1.0-bin/conf export PATH=$HIVE_HOME/bin:$PATH export CLASSPATH=$CLASSPATH:/home/woir/hadoop-2.6.0/lib/*:. export CLASSPATH=$CLASSPATH:/home/woir/apache-hive-2.1.0-bin/lib/*:. export HADOOP_HOME=~/hadoop-2.6.0 hduser@laptop:/home/woir/apache-hive-2.1.1-bin$ source ~/.bashrc $ echo $HADOOP_HOME /home/woir/hadoop-2.6.0 $ hive –version Hive 2.1.0 Subversion git://jcamachguezrMBP/Users/jcamachorodriguez/src/workspaces /hive/HIVE-release2/hive -r 9265bc24d75ac945bde9ce1a0999fddd8f2aae29 Compiled by jcamachorodriguez on Fri Jun 17 01:03:25 BST 2016 From…
Read more
Running an external jar from Aws Hadoop
Hadoop AWS First select the services and click on EMR from Analytics. Then click on the add cluster. Fill the Details of Cluster. Cluster name as Ananthapur-jntu Here we are checking the Logging Browse the s3 folder with the amar2017/feb Launch mode should be Step Extension After that select step type as custom…
Read more

Hadoop Word Count Problem
Few basics in Unix – UNIX TUTORIAL How to check if a process is running or not # ps -eaf | grep ‘java’ will list down all the process which uses java How to kill a process forcefully # ps -eaf | grep ‘java’ The above command shows the process ids of the process which…
Read more
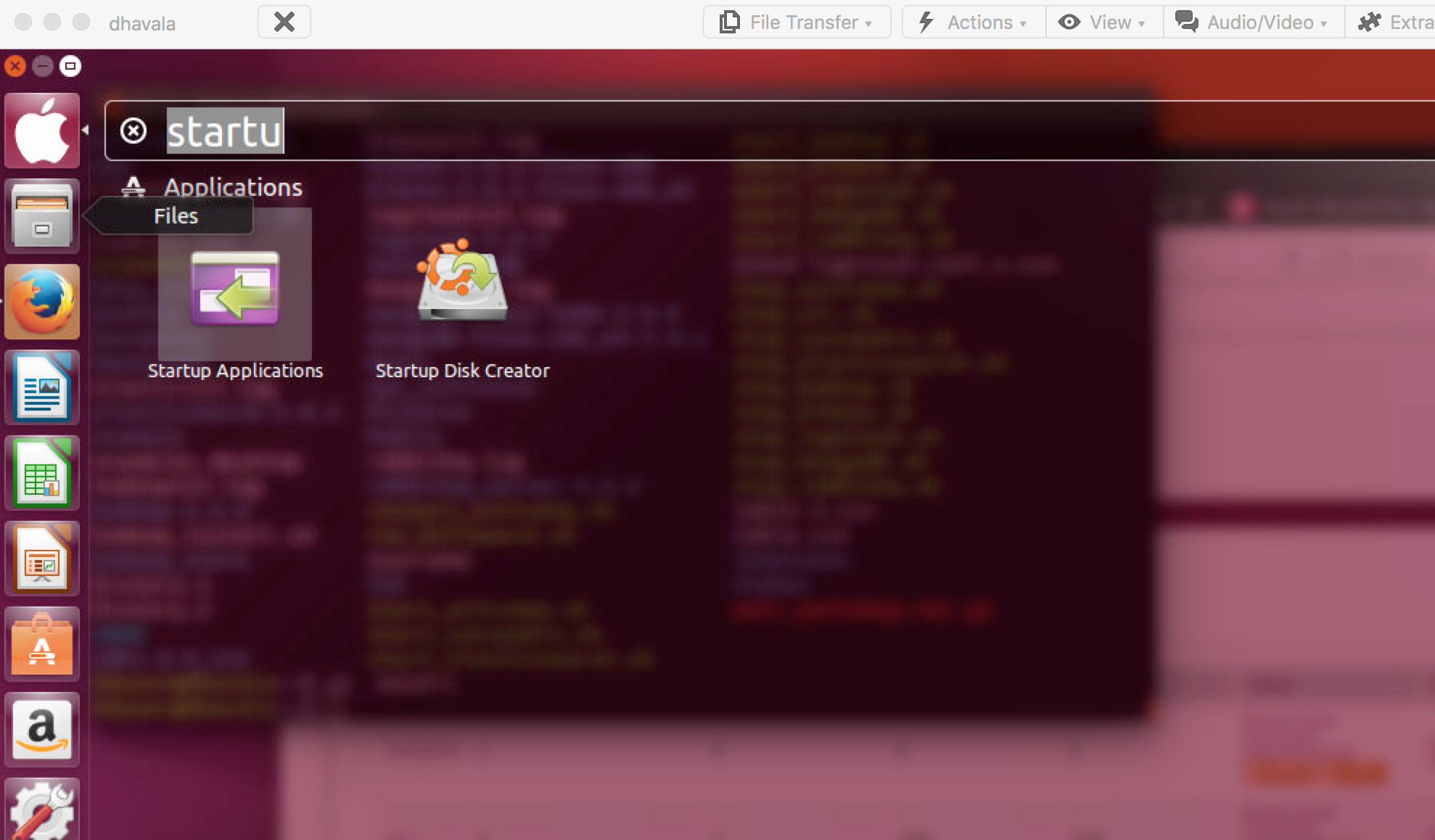
Installer for Ubuntu
Please create a new user with sudo permission username – hduser Login to the system with the new user Setup ssh server sudo apt-get install ssh Uncheck the option in Startup Application RESTART BOX Install JPS – Please ensure ‘jps’ command is available. If not please type following to install it sudo apt-get install openjdk-7-jdk…
Read more