Hadoop Word Count Problem

Few basics in Unix –
- How to check if a process is running or not
# ps -eaf | grep 'java' will list down all the process which uses java
- How to kill a process forcefully
# ps -eaf | grep 'java'
The above command shows the process ids of the process which uses java
# kill -9 'process id' it will kill the job with that process id
- What does sudo do –
- It runs the command with root’s privilege
Start Desktop
- Start Desktop Box
- Login as amar
- Click on the right top corner and Chose Hadoop User.
- Enter password – <your password>

- Click on the Top Left Ubuntu Button and search for the terminal and click on it.
- You should see something similar as below
Start with HDFS
- Setup the environment
# source /home/woir/sourceme
- Stop all the processes
# /home/woir/stop_all.sh
- Start hadoop if not already started –
# /home/woir/start_hadoop.sh
- Check if Hadoop is running fine
# jps it will list down the running hadoop processes. o/p should look like below - woir@woir-VirtualBox:/usr/local/hadoop/sbin$ jps 14416 SecondaryNameNode 14082 NameNode 14835 Jps 3796 Main 14685 NodeManager 14207 DataNode 14559 ResourceManager
- Make directory for the purpose of demonstration
The command creates the /user/woir/dir/dir1 and /user/woir_hadoop/employees/salary
# hadoop fs -mkdir -p /user/woir_hadoop/dir/dir1 /user/woir_hadoop/employees/salary
- Copy contents in to the directory. It can copy directory also.
# hadoop fs -copyFromLocal /home/woir/example/WordCount1/file* /user/woir_hadoop/dir/dir1
- The hadoop ls command is used to list out the directories and files –
# hadoop fs -ls /user/woir_hadoop/dir/dir1/
- The hadoop lsr command recursively displays the directories, sub directories and files in the specified directory. The usage example is shown below:
# hadoop fs -lsr /user/woir_hadoop/dir
- Hadoop cat command is used to print the contents of the file on the terminal (stdout). The usage example of hadoop cat command is shown below:
# hadoop fs -cat /user/woir_hadoop/dir/dir1/file*
- The hadoop chmod command is used to change the permissions of files. The -R option can be used to recursively change the permissions of a directory structure.
Note the permission before –
# hadoop fs -ls /user/woir_hadoop/dir/dir1/
Change the persission-
# hadoop fs -chmod 777 /user/woir_hadoop/dir/dir1/file1
See it again –
# hadoop fs -ls /user/woir_hadoop/dir/dir1/
- The hadoop chown command is used to change the ownership of files. The -R option can be used to recursively change the owner of a directory structure.
# hadoop fs -chown amars:amars /user/woir_hadoop/dir/dir1/file1
Check the ownership now –
# hadoop fs -ls /user/woir_hadoop/dir/dir1/file1
- The hadoop copyFromLocal command is used to copy a file from the local file system to the hadoop hdfs. The syntax and usage example are shown below:
# hadoop fs -copyFromLocal /home/woir/example/WordCount1/file* /user/woir_hadoop/employees/salary
- The hadoop copyToLocal command is used to copy a file from the hdfs to the local file system. The syntax and usage example is shown below:
# hadoop fs -copyToLocal /user/woir_hadoop/dir/dir1/file1 /home/woir/Downloads/
- The hadoop cp command is for copying the source into the target.
# hadoop fs -cp /user/woir_hadoop/dir/dir/file1 /user/woir_hadoop/dir/
- The hadoop moveFromLocal command moves a file from local file system to the hdfs directory. It removes the original source file. The usage example is shown below:
# hadoop fs -moveFromLocal /home/woir/Downloads/file1 /user/woir_hadoop/employees/
- It moves the files from source hdfs to destination hdfs. Hadoop mv command can also be used to move multiple source files into the target directory. In this case the target should be a directory. The syntax is shown below:
# hadoop fs -mv /user/woir_hadoop/dir/dir1/file2 /user/woir_hadoop/dir/
- The du command displays aggregate length of files contained in the directory or the length of a file in case its just a file. The syntax and usage is shown below:
# hadoop fs -du /user/woir_hadoop
- Removes the specified list of files and empty directories. An example is shown below:
# hadoop fs -rm /user/woir_hadoop/dir/dir1/file1
- Recursively deletes the files and sub directories. The usage of rmr is shown below:
# hadoop fs -rmr /user/woir_hadoop/dir
Web UI
NameNode daemon
-
# http://localhost:50070/
Log Files
-
# http://localhost:50070/logs/
Explore Files
-
# http://localhost:50070/explorer.html#/
Status
-
# http://localhost:50090/status.html
Hadoop Word Count Example
Go to home directory and take a look on the directory presents
-
# cd /home/woir
-
# 'pwd' command should show path as '/home/woir'.
-
execute 'ls -lart' to take a look on the files and directory in general.
- Confirm that service is running successfully or not
-
# run 'jps' - you should see something similar to following -
-
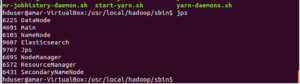
Go to example directory –
-
# cd /home/woir/example/WordCount1/
- Run command ‘ls’ – if there is a directory named ‘build’ please delete that and recreate the same directory. This step will ensure that your program does not uses precompiled jars and other files
# ls -lart # rm -rf build # mkdir build
- Remove JAR file if already existing
-
# rm /home/woir/example/WordCount1/wcount.jar
-
- Ensure JAVA_HOME and PATH variables are set appropriately
# echo $PATH # echo $JAVA_HOME JAVA_HOME should be something like /home/woir/JAVA PATH should have /home/amar/JAVA/bin in that.
- If the above variables are not set please do that now
# export JAVA_HOME=/home/woir/JAVA
# export PATH=$JAVA_HOME/bin:$PATH
- Set HADOOP_HOME
# export HADOOP_HOME=/home/woir/hadoop-2.6.0
- Build the example ( please make sure that when you copy – paste it does not leave any space between the command) –
-
# $JAVA_HOME/bin/javac -classpath $HADOOP_HOME/share/hadoop/common/hadoop-common-2.6.0.jar:$HADOOP_HOME/share/hadoop/common/lib/hadoop-annotations-2.6.0.jar:$HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-client-core-2.6.0.jar -d build WordCount.java
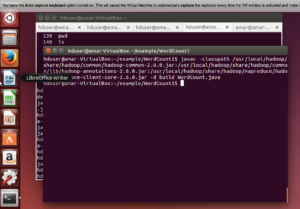
- Create Jar –
-
# jar -cvf wcount.jar -C build/ .
-
- Now prepare the input for the program ( please give ‘output’ directory your own name – it should not be existing earlier )
- Make your own input directory –
-
# hadoop dfs -mkdir -p /user/woir_hadoop/input
-
- Copy the input files ( file1, file2, file3 ) to hdfs location
-
# hadoop dfs -put file* /user/woir_hadoop/input
-
- Check if the output directory already exists.
# hadoop dfs -ls /user/woir_hadoop/output - If it already existing delete with the help of following command –
- Make your own input directory –
# hadoop dfs -rm /user/woir_hadoop/output/* # hadoop dfs -rmdir /user/woir_hadoop/output
- Run the program
# hadoop jar wcount.jar org.myorg.WordCount /user/woir_hadoop/input/ /user/woir_hadoop/output
At the end you should see something similar –
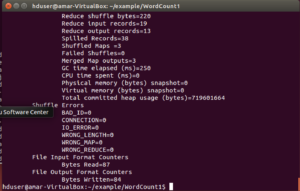
- Check if the output files have been generated
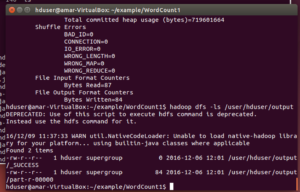
# hadoop dfs -ls /user/woir_hadoop/output
you should see something similar to below screenshot
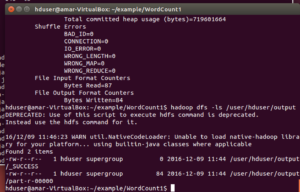
- Get the contents of the output files –
# hadoop dfs -cat /user/woir_hadoop/output/part-r-00000
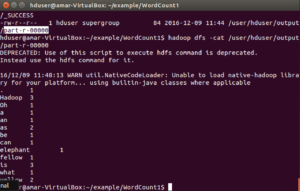
- Verify the word count with the input files-
# cat file1 file2 file3
The words count should match.
Word Count Program for day 2 morning sessions
Steps
- Go to the directory where your program is located
-
cd /home/woir/example/WordCount1/
- Check your program
-
ls WordCount.java
-
-
- Cleanup the existing jars and build directory
-
rm -rf build
-
rm -rf *.jar
-
- Create build directory
-
mkdir build
-
- Confirm if your program has generated required class files.
- ls -lR build
- Compile and make the jar of your java program
-
$JAVA_HOME/bin/javac -classpath $HADOOP_HOME/share/hadoop/common/hadoop-common-2.6.0.jar:$HADOOP_HOME/share/hadoop/common/lib/hadoop-annotations-2.6.0.jar:$HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-client-core-2.6.0.jar -d build WordCount.java
-
- Prepare JAR out of it
-
jar -cvf wcount.jar -C build/ .
-
- Check the jar file is created or not –
-
ls *.jar
-
- Prepare inputs – copy the required input files to hdfs
-
hadoop dfs -mkdir -p /user/vasavi/input
-
hadoop dfs -copyFromLocal file* /user/vasavi/input
-
- Confirm if your files copied to the correct locations
- hadoop dfs -ls /user/vasavi/input
- Clear the existing output director
-
hadoop dfs -rmr /user/vasavioutput
-
- Run the program
-
hadoop jar wcount.jar org.myorg.WordCount /user/vasavi/input /user/vasavi_output
-
- Confirm if your o/p is ready
-
hadoop dfs -ls /user/vasavi_output
-
- See the output results
-
hadoop dfs -cat /user/vasavi_output/*
-
Dictionary Problem
- Copy Java File and save as UnifiedDict.java
package org.myorg;
import java.io.IOException;
import java.util.regex.Pattern;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
public class UnifiedDict extends Configured implements Tool {
public static void main(String[] args) throws Exception {
int res = ToolRunner.run(new UnifiedDict(), args);
System.exit(res);
}
public int run(String[] args) throws Exception {
Job job = Job.getInstance(getConf(), "wordcount");
job.setJarByClass(this.getClass());
// Use TextInputFormat, the default unless job.setInputFormatClass is used
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
return job.waitForCompletion(true) ? 0 : 1;
}
public static class Map extends Mapper<LongWritable, Text, Text, Text> {
public void map(LongWritable offset, Text lineText, Context context)
throws IOException, InterruptedException {
String line = lineText.toString();
String [] keyvalue = line.split("=");
context.write(new Text(keyvalue[0]),new Text (keyvalue[1]));
}
}
public static class Reduce extends Reducer<Text, Text, Text, Text> {
@Override
public void reduce(Text word, Iterable<Text> counts, Context context)
throws IOException, InterruptedException {
String totalString = " = ";
for (Text count : counts) {
String V1 = count.toString();
totalString= totalString + "|" + V1;
}
context.write(word, new Text ( totalString ));
}
}
}
Copy Input as given below -
save in a file named k1
E1=H1
E2=K2
E1=T1
save in a file named k2
E3=H3
E4=H4
E5=T5
$JAVA_HOME/bin/javac -classpath $HADOOP_HOME/share/hadoop/common/hadoop-common-2.6.0.jar:$HADOOP_HOME/share/hadoop/common/lib/hadoop-annotations-2.6.0.jar:$HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-client-core-2.6.0.jar -d build UnifiedDict.java jar -cvf unifieddict.jar -C build/ . hadoop dfs -mkdir /user/woir_hadoop/dict_input hadoop dfs -copyFromLocal k1 k2 /user/woir_hadoop/dict_input/ hadoop jar wcount.jar org.myorg.WordCount /user/woir_hadoop/dict_input/ /user/woir_hadoop/output_dict hadoop dfs -cat /user/woir_hadoop/output_dict/*
Download –
Create database <DatabaseName>
-> create database woir ; create database woir_training; show databases; drop database woir_training; create database woir_vasavi; use woir_vasavi;
-> show tables ; -> create table employees_woir(Id INT, Name STRING, Age INT, Address STRING, Salary FLOAT, Department STRING) Row format delimited Fields terminated by ','; -> LOAD DATA LOCAL INPATH '/home/woir/Downloads/employee.csv' INTO table employees_woir; -> create TABLE order_history (OrderId INT,Date1 TIMESTAMP, Id INT, Amount FLOAT) ROW Format delimited Fields terminated by ','; -> LOAD DATA LOCAL INPATH '/home/woir/Downloads/order.csv' INTO table order_history;
-> show tables;
-> select * from employees_woir;
-> select salary from employees_woir;
-> select sum ( salary ) from employees_woir;
-> select avg ( salary ) from employees_woir;
-> select max ( salary ) from employees_woir;
-> select min ( salary ) from employees_woir;
To create the internal table
-> CREATE TABLE woirhive_internaltable (id INT,Name STRING) Row format delimited Fields terminated by ',';
Load the data into internal table
-> LOAD DATA LOCAL INPATH '/home/woir/Downloads/names.csv' INTO table woirhive_internaltable;
Joins are of 4 types, these are –
- Inner join
- Left outer Join
- Right Outer Join
- Full Outer Join
Inner Join:
-> SELECT c.Id, c.Name, c.Age, o.Amount FROM employees_woir c JOIN order_history o ON(c.Id=o.Id);
Left Outer Join:
-> SELECT c.Id, c.Name, o.Amount, o.Date1 FROM employees_woir c LEFT OUTER JOIN order_history o ON(c.Id=o.Id)
Right outer Join:
-> SELECT c.Id, c.Name, o.Amount, o.Date1 FROM employees_woir c RIGHT OUTER JOIN order_history o ON(c.Id=o.Id)
Full outer join:
-> SELECT c.Id, c.Name, o.Amount, o.Date1 FROM woir_employees c FULL OUTER JOIN order_history o ON(c.Id=o.Id)