Start Virtual Box, Choose the machine you prepared in earlier step and click on the “Start” button ( green color ).
If asked for please enter password ‘abcd1234’
Click on the Ubuntu on the top-left corner and look for terminal and click on the terminal
Once the terminal is up and running it should look similar to following –
Login as hduser user.
su hduser
password ‘abcd1234’
Go to home directory and take a look on the directory presents
cd /home/hduser
‘pwd’ command should show path as ‘/home/hduser’.
execute ‘ls -lart’ to take a look on the files and directory in general.
Start hadoop
cd /usr/local/hadoop/sbin/
./start-all.sh
Confirm that serivce is running successfully or not
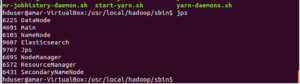
run ‘jps’ – you should see something similar to following –
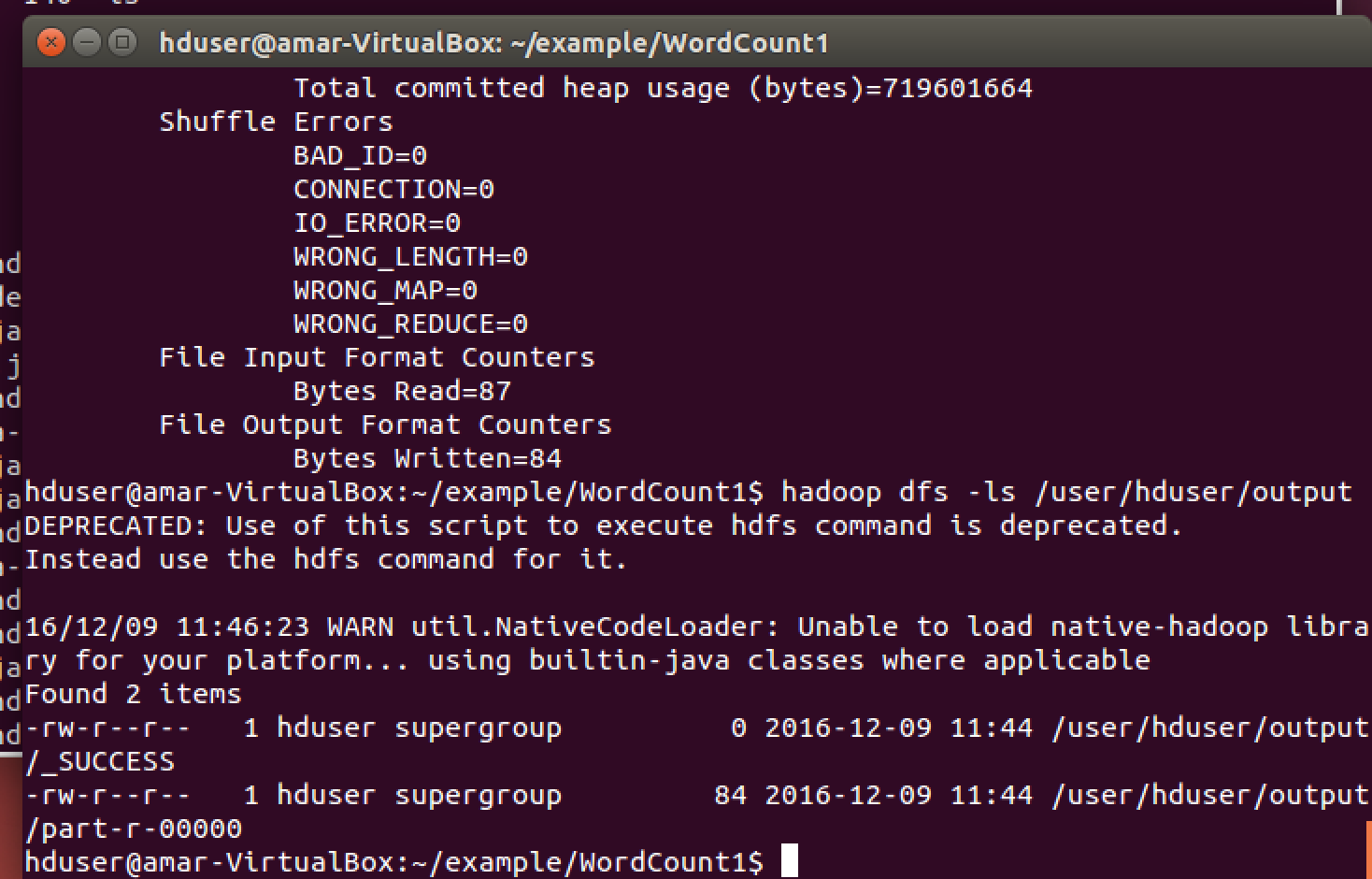
Go to the cd /home/hduser/example/WordCount1/
Run command ‘ls’ – if there is a directory named ‘build’ please delete that and recreate the same directory. This step will ensure that your program does not uses precompiled jars and other files
rm -rf build
mkdir build
Set JAVA_HOME and update PATH
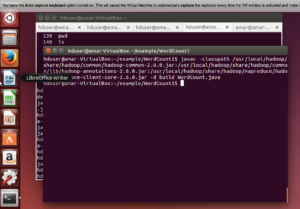
Build the example ( please make sure that when you copy – paste it does not leave any space between the command) –